伦理小说在线阅读 反向和错位图灵测试:GPT-4比东谈主类更「东谈主性化」

剪辑:lumina伦理小说在线阅读
【新智元导读】加州大学的筹商东谈主员通过反向和错位图灵测试,探讨了东谈主类和AI在永别对话者是东谈主类如故AI时的材干。但收尾标明,在不进行主动互动时,不管是东谈主类如故现时的大讲话模子王人难以永别二者。
由AI生成的内容逐渐充斥了互联网。
目下的东谈主们比起径直与AI进行对话,更多的是在阅读和浏览AI生成的文本。
而经典的图灵测试赋予了评判者一个要津上风:他们不错及时休养问题,以对参与者进行挣扎性测试。
但这在被迫耗尽AI生成文本时并不老是存在。
因此,来自加州大学圣地亚哥分校的筹商者提议,咱们需要在更接近实践的环境中,开展图灵测试的变体,以笃定东谈主们在实践场景中永别东谈主类和AI的成果。

并进一步理清以下问题:
东谈主类是否大致仅通过不雅察对话来可靠地永别东谈主类与AI?
LLM是否不错四肢AI检测器,不仅适用于静态文本(如著作和段落),还适用于动态对话?
错位图灵测试会进步如故裁减准确性?
反向图灵测试能否揭示东谈主工系统中的朴素心境学?
以及在实践天下的对话环境中,哪些轮番最允洽进行AI检测?
这项筹商将通过两种图灵测试的变体——「反向图灵测试」(inverted Turing test)和「错位图灵测试」(displaced Turing test),来测量东谈主类和大讲话模子在这种永别上的进展。
其中,GPT-3.5、GPT-4,以及四肢评判者的东谈主类基于图灵测试的对话记载判断参与者是东谈主类如故AI。
经典图灵测试与其系列变体
经典图灵测试
在经典的图灵测试中,一位东谈主类评判者与两位参与者进行纯文本对话,其中一位是东谈主类,另一位是机器。
要是评判者无法准确永别东谈主类和盘算机,那么盘算机就通过了测试,可被视为智能体。
自图灵的原始论文发表以来,图灵测试掀翻了热烈的狡辩,对当代智能见地的剖析和构建起到了要津作用。
但另一方面,它四肢智能测试的有用性或充分性也受到了等闲质疑。
可岂论其四肢智能测试的有用性怎么,图灵测试仍然是评估东谈主类和AI写稿相似性的伏击妙技,亦然筹商AI欺骗活动的有劲器具。
多年来,已有多个通过图灵测试的尝试,包括1990年至2020年间的Loebner奖竞赛,但莫得任何系统通过该测试。
「HumanorNot」是一个大范围的社会图灵测试实验,发现评判者的准确率为60%;2024年的一项筹商证明了第一个通过率与当场水平(54%)无统计学各异但仍低于东谈主类圭臬(67%)的系统。
图灵测试存在多种变体,每种变体王人为表面和奉行提供了不同的视角。
反向图灵测试(Inverted TuringTest)
反向图灵测试,即让AI系统担任评判者的变装。
1996年,Watt提议了反向测试四肢一种「朴素心境学」的测量轮番,即东谈主类天生具有识别与自己相似的智能并将其归因于其他心智的倾向。
要是AI系统「无法永别两个真东谈主,或无法永别一位东谈主类和一台通过宽泛图灵测试的机器,但大致永别一位东谈主类和一台在有真东谈主不雅察者的宽泛图灵测试中不错分辨出来的机器」,则该测试通过。
Watt合计,通过让AI充任不雅察者变装,并将其对不同参与者的判断与东谈主类的准确性进行相比,不错揭示AI是否具有东谈主类访佛的朴素心境学。
错位图灵测试(Displaced TuringTest)
错位图灵测试,即让评判者阅读由另一位东谈主类或AI评判者先前进行的互动图灵测试的对话记载,从而评估AI的进展。
新的评判者被刻画为「错位」的,因为他们「耳旁风」,未尝参与和AI的互动。
这是一种新的静态图灵测试,因为判断基于事先存在且不变的、由东谈主类或AI生成的内容。
其次,在传统图灵测试中,互动评判者不错提议动态、生动且挣扎性的问题,而静态图灵测试中的评判者只可基于对话内容进行判断,无法通过互动来真切探讨最有用的问询标的。
静态测试在评估模子材干时有一定局限性,但它们很可能反应了实践天下中的常见情况,因为好多互动是由更等闲的不雅众阅读的,而不单是是径直的对话当事东谈主。
统计轮番检测AI生成内容
目下存在多种统计轮番来检测AI生成的内容。这些轮番主要基于大讲话模子(LLM)通过对词语的概率散布进行采样生成内容的旨趣:
这可能会留住特定的概率特征,举例LLM生成的内容在统计概率上比东谈主类生成的内容更可能出现。
2023年,Mitchell等东谈主树立了一种联系宗旨「曲率」,它通过使用掩码讲话模子生成的小扰动来权衡一段文本的局部最优性,LLM生成的内容相关于隔壁的扰动更可能是最优的。
2024年,Mireshghallah等东谈主发现,较小的LLM频频是更好的检测模子,其中具有125m参数的OPT模子在检测AI生成内容时进展最好,在检测GPT-4内容时达到了90%的准确率。
基于这些轮番和其他文天职类盘算轮番,一经树立了多样营业器具。筹商在不同环境中评估了这些轮番的有用性,收尾不一:诚然在某些界限中准确性较高,但模子频频不能靠,可能会产生误报。
反向图灵测试
在反向图灵测试中,GPT-3.5和GPT-4饰演裁定者的变装,评估先前图灵测试的笔墨记载以判断参与者是东谈主类如故AI。
筹商设定了五个假定:
1.GPT-4的准确率是否权贵高于或低于东谈主类的准确率。
2.GPT-4是否也难以准确识别参与者。
3.模子是否更倾向于将真东谈主类判断为东谈主类,而非将最好的GPT-4参与者判断为东谈主类。
4.GPT-4四肢裁定者在较长的笔墨记载中是否会进展出更高的准确率。
5.GPT-4四肢裁定者的准确率是否高于GPT-3.5。
探讨了这两个模子的识别准确性,以及对话长度和模子质料对判断的影响、以及大讲话模子的质料在判断笔墨记载中的作用。
轮番
使用Jones和Bergen在2023年的筹商中杰出6000次图灵测试的笔墨记载。
其中,Jones和Bergen筹商中的AI参与者基于以下三个模子:GPT-3.5、GPT-4和ELIZA。
何况,样本需要平衡东谈主类和AI参与者的数目,以及进展最好的GPT-4参与者的游戏比例与通盘这个词数据筹划的比例相易。并确保进展最好模子的东谈主类和东谈主工智能判决散布相易。
模子需判断参与者的类型,并指出其判决的信心进程,同期提供判断依据。
收尾
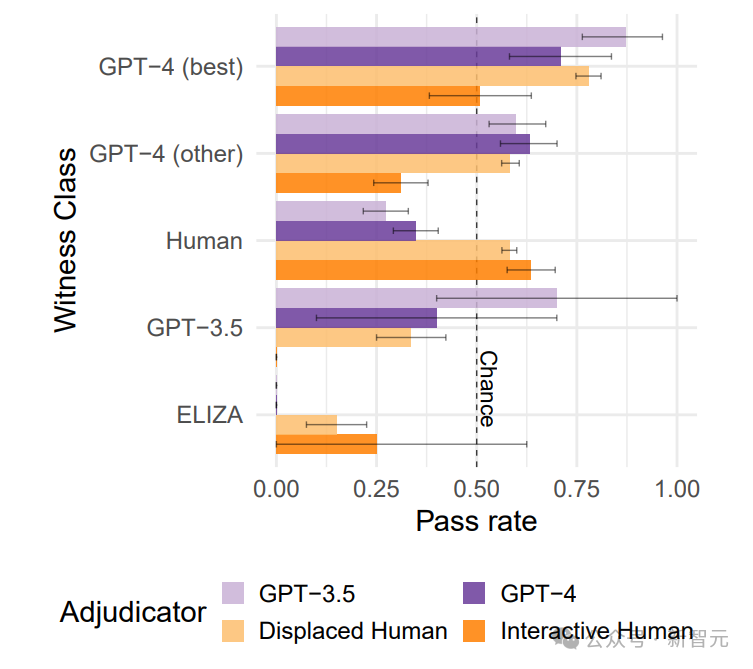
GPT-4四肢裁定者的准确性权贵低于互动东谈主类裁定者,尤其是在判断进展最好的AI参与者时,准确率低于当场水平。
笔墨记载长度和模子质料(GPT-4 vs GPT-3.5)瞄准确性莫得权贵影响。
辩论
在反向图灵测试中,两个AI系统四肢裁定者的准确性均低于互动东谈主类评判者,尤其是在面临进展最好的AI参与者时,准确性更低。
AI参与者的通过率高于东谈主类参与者,这意味着AI裁定者更容易将AI参与者误判为东谈主类,同期将东谈主类参与者误判为AI。
这些收尾标明,现时的大讲话模子在永别东谈主类和AI生成的内容方面进展欠安——即使它们正在评估由相易大讲话模子生成的内容。
对此收尾的一个可能阐明注解是,这些系统的输出受其对东谈主类磨真金不怕火数据的表征所启动。
因此,模子可能空泛大致永别自己输出与其师法的磨真金不怕火数据之间各异的邃密或潦倒文敏锐的表征。
现时的大讲话模子不适配合为检测对话中AI孝敬的有用器具。
错位图灵测试
错位图灵测试评估东谈主们在无法径直与AI互动环境中,如阅读支吾媒体对话来识别AI的准确性。
在这项测试中,参与者四肢东谈主类裁定者,证据笔墨记载样本判断参与者是否为东谈主类或AI。
筹商设定了与反向图灵测试访佛的一组问题。
轮番
将相易的500份笔墨记载样本展示给加州大学圣迭戈分校的学生(共109东谈主,其中84名女性,年岁范围为19至31岁),每位参与者当场采纳到50份笔墨记载的子集。
每份记载平均由10名参与者进行判断。
参与者需要为每份记载指出他们的信心水柔顺判断依据。并通过使用R讲话中的lmertest包拟合线性混杂效应模子。
收尾
错位东谈主类裁定者的识别准确性低于互动的东谈主类裁定者,尤其是在识别基于GPT的AI模子时。
长度较短的笔墨记载似乎对裁定者更有匡助。
辩论
错位环境加多了识别大讲话模子AI的挑战,辞谢了参与者进行挣扎性究诘或不雅察参与者的响应技能,可能导致他们作念出更快的决策或干涉较少的元气心灵。
在实践场景中,当东谈主类裁定者无法径直审问文本内容的开首时,这些收尾标明东谈主们可能难以可靠地永别东谈主类和AI生成的内容。
与反向图灵测试访佛,进展最好的GPT-4参与者的通过率高于东谈主类参与者。
这标明伦理小说在线阅读,在阅读东谈主类与AI模子之间的在线对话时,AI系统可能更容易被判断为东谈主类,而确凿的东谈主类反而不易被识别。
另外,笔墨记载长度瞄准确性的负面影响似乎违背直观:为什么较少的信息反而对裁定者更有匡助?
事实上,这种反常气候可能是由于次要混杂成分导致的,很是是在笔墨记载长度的笃定步地上。
在原始筹商中,裁定者不错聘请提前达成对话,当他们驯服我方在与东谈主类或AI交流时,可能会这样作念。
因此,较短的笔墨记载更可能包含对互动裁定者很是有匡助的信息,也可能相似匡助了错位裁定者。
收尾分析
语境分析
错位东谈主类实验与反向实验之间的一个要津区别在于,东谈主类裁定者是承接完成 50 份笔墨记载的,而大讲话模子裁定者则是一一呈现每份记载。
筹商发现,承给与束文本记载的步地可能匡助东谈主类裁定者更好地掌抓文本记载的举座趋势,并识别重迭出现的AI参与者的特征,从而逐渐进步判断的准确性。
为了测试是否承接呈现记载也能进步AI裁定者的进展,筹商东谈主员进行了访佛的实验,承接向GPT-4展示文本记载。
收尾涌现,通过这种步地,GPT-4的准确率从36.4%进步到58%,接近东谈主类裁定者的进展。
此外,当究诘GPT-4其判断计谋时,GPT-4暗意其计谋由单纯查验语法逐渐转向评估对话的一致性、幽默和热诚各异、长久潦倒文关联等复杂成分,涌现了其在识别确实东谈主类对话时的朝上。
这标明承接的文本呈现不错增强裁定者,不管是东谈主如故AI,对文本特征的剖析和识别材干。
原因分析
为了评估不同裁定者在评判文本记载是由东谈主如故AI生成时依赖的决策根由,筹商使用了GPT-4o模子,证据一种预设的分类决策来分析裁定者的判断根由。
这个决策由Jones和Bergen提供,旨在捕捉和分类裁定者为其决策提供的具体根由。
筹商收尾涌现,不管是AI裁定者如故东谈主类裁定者,他们援用的根由类型有很大的相似性。
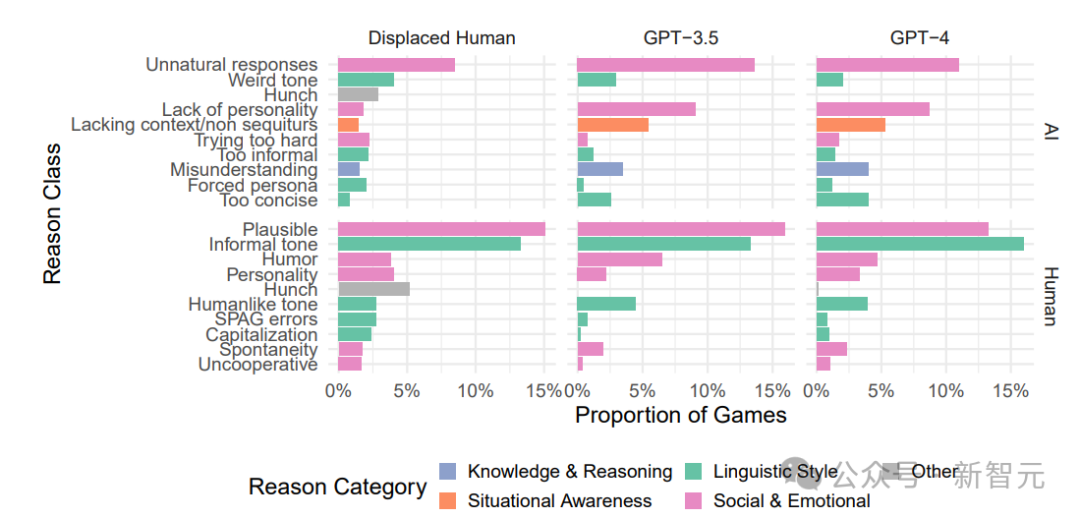
在判断对话来自AI时,最常见的根由是对话内容显得「不当然」。
AI裁定者在判断时,更多地柔和对话者是否展示出东谈主类突出的社会热诚性格,如个性的缺失。而东谈主类裁定者的根由散布则相对更平衡,涵盖多个不同的类别。
当判断对话来自东谈主类时,三种裁定者频繁王人会指出对话中的合理复兴和非厚爱口吻,同期也会柔和社会热诚成分和讲话作风。
这标明,岂论裁定者是东谈主如故AI,在进行决策时,他们王人倾向于强调对话中的相似特征,这些特征匡助他们永别东谈主类和AI生成的内容。
统计东谈主工智能检测轮番
为了筹商应用统计轮番在图灵测试中检测AI生成的内容的有用性,筹商使用了Mireshghallah等东谈主提议的两种主要轮番:一种是测量笔墨记载中的平均对数似然值,另一种是测量曲率。
对数似然值是指在给定前置词的情况下,盘算文本内容生成的可能性;曲率则是通过相比文本与其相似内容的概率各异来进行评估。
使用OPT-125m模子进行实验,收尾标明,这两种轮番在永别AI和东谈主类生成的文本方面有不同的成果。
对数似然轮番得出的举座准确率为62%,而曲率轮番的准确率更高,达到了69%。
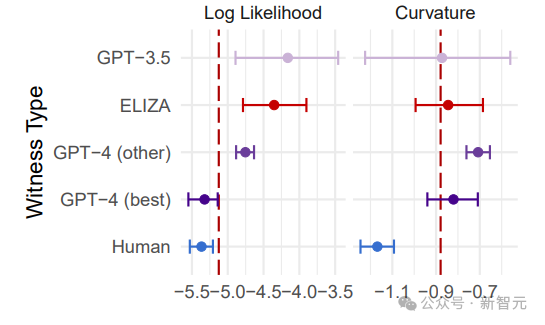
曲率轮番尤其有用,因为它能更好地永别东谈主类和AI生成的文本,尤其是在管束最新和最高档的AI模子(如GPT-4)时。
这些发现标明,尽管这些统计轮番提供了一种永别东谈主类和AI文本的器具,但在管束伊始进的AI模子时,它们的可靠性仍有待进步。
改日的筹商需要探讨更多的统计轮番,以进步在这种环境下的检测准确性。
追忆
朴素心境学
Watt对通过反向图灵测试的圭臬是机器的进展应与东谈主类评估者绝顶。
要是东谈主类评估者大致永别东谈主类和特定的AI,那么AI裁定者也应大致作念到。要是东谈主类无法永别,那么机器也应该失败。
筹商中发现,GPT-4的判断准确性与错位东谈主类裁定者绝顶,两者的准确率王人在58%摆布。
通过潦倒文体习(ICL),GPT-4的进展致使进步到与东谈主类简直一致的水平。
然而,尽管准确率相似,GPT-4与东谈主类裁定者的空幻模式却不同,这标明两者在念念维和判断历程中存在根蒂各异。
这些发现支撑了Watt的表面,即AI的念念维模子与东谈主类裁定者的模子存在系统性的各异。
改日的筹商不错通过加多互动性和系统性地修改文本记载的特征来进一步探讨东谈主类和AI在念念维步地上的不同。
这些筹商有助于更好地剖析AI在模拟东谈主类心境状况方面的后劲和局限。
骨子检测
骨子检测指的是在日常生存中常见的环境,如支吾媒体和论坛,评估东谈主和AI之间对话的确实性。
这类环境中的图灵测试频繁是的,因为不雅察者无法径直与对话者互动来考证他们是否为AI。
筹商发现,在这种环境下,不管是GPT-4如故东谈主类裁定者,在永别AI和东谈主类时王人进展欠安,尤其是面临进展精湛的AI时,这些AI频频大致比确凿的东谈主类更得手地伪装我方。
统计AI检测轮番,如分析话语曲率,显透露在永别东谈主类和AI生成音信时的后劲,ROC分析涌现这种轮番的准确率不错达到69%。
然而,骨子应用中的误报问题可能会对确实用户产生不利影响,标明这种轮番在骨子场景中的司法。
筹商还发现,教会的积贮可能进步裁定者的判断准确性,错位东谈主类裁定者和GPT-4在屡次判断后王人进展出纠正的趋势。
改日的筹商不错通过予以参与者反馈来探索学习成果,或者进一步探讨不同裁定器具之间的互相影响。这些发现强调了在骨子环境中AI检测的复杂性和挑战。
论断
在反向图灵测试中,GPT-3.5和GPT-4四肢AI裁定者,以及错位图灵测试中的东谈主类裁定者王人参与了评判对话中某个参与者是否为东谈主类。
但收尾涌现,不管是AI裁定者如故错位东谈主类裁定者,在被迫阅读的情境下,他们的准确性王人低于径直互动的原始图灵测试中的裁定者。
这标明,在不进行主动互动时,不管是东谈主类如故现时的大讲话模子王人难以永别二者。